(通訊員 劉小磊)近日,國際學術期刊Genome Biology在線發表了題為(wei) “KAML: improving genomic prediction accuracy of complex traits using machine learning determined parameters”的研究論文。該研究提出了一種準確性高且計算高效的基因組預測方法,該方法利用機器學習(xi) 的策略解析基因組和表型組大數據之間的隱藏關(guan) 係,並根據表型的遺傳(chuan) 複雜程度智能化選擇最優(you) 預測模型來提高基因組預測的準確性。
基因組預測是指利用覆蓋於(yu) 基因組的高密度遺傳(chuan) 標記對未知表型(或育種值)進行預測的技術。在動植物領域,利用該技術可對不同經濟性狀進行早期選擇,保留優(you) 勢個(ge) 體(ti) ,淘汰劣勢個(ge) 體(ti) ,既能提高群體(ti) 總體(ti) 性能表現以獲得豐(feng) 厚的經濟效應,還能極大降低飼養(yang) 及表型測量成本;對於(yu) 人類,基因組預測可根據遺傳(chuan) 標記信息估計各類遺傳(chuan) 疾病的患病風險,給人們(men) 的生活方式及飲食習(xi) 慣提供針對性建議,保障人們(men) 的健康生活。預測準確性是基因組預測應用於(yu) 實際的基本保證,而統計方法發揮至關(guan) 重要的作用。線性混合模型(LMM)以其高效的計算效率優(you) 勢成為(wei) 目前基因組預測使用最廣泛的方法,然而由於(yu) 其簡單的標記效應假設,預測準確性往往偏低,尤其對於(yu) 受大效應基因影響的性狀。另一類以貝葉斯(Bayes)理論為(wei) 基礎的方法,大多具有複雜的標記效應假設,模型靈活多變,能夠適用於(yu) 遺傳(chuan) 構建從(cong) 簡單到複雜的性狀,預測準確性往往高於(yu) LMM方法,然而其複雜的假設導致眾(zhong) 多的未知待估超參,參數的求解過程無法並行運算,計算效率低下,尤其對於(yu) 超高密度標記,預測一個(ge) 性狀可能需要數周甚至數月的時間,因此難以廣泛應用於(yu) 育種實踐。
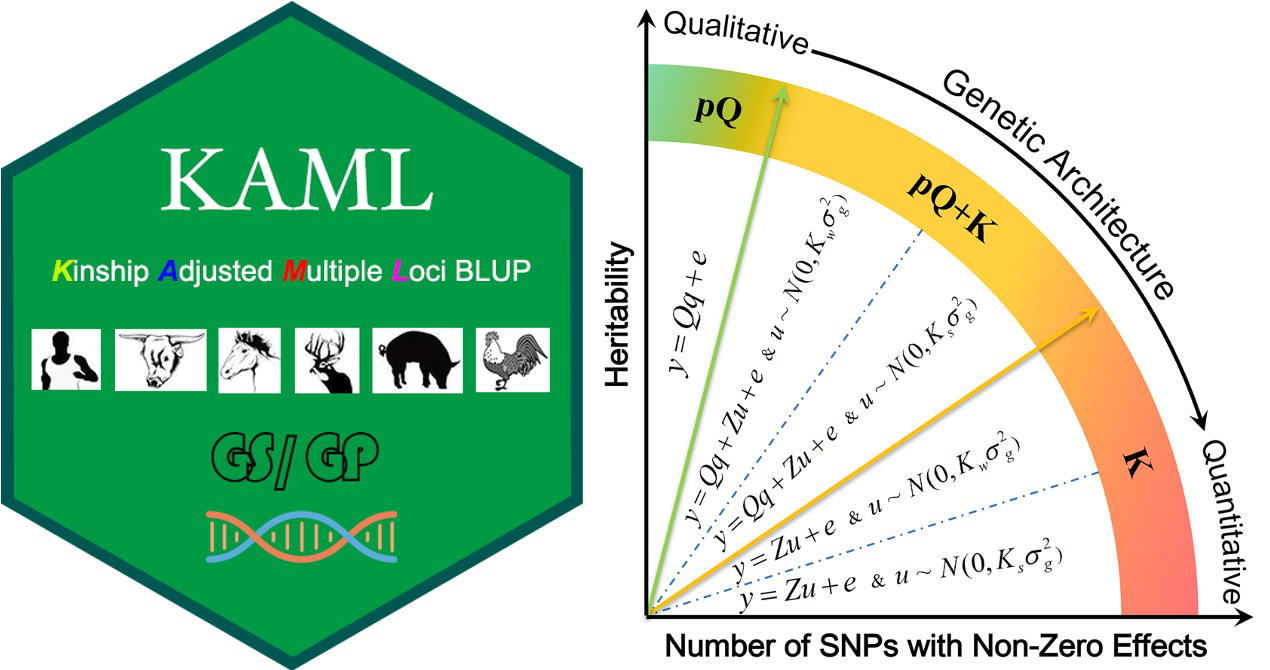
高計算效率的方法預測準確性較低,高預測準確性的方法計算效率較低。為(wei) 了解決(jue) 這一難題,該研究結合兩(liang) 類方法的特性,提出了一種準確性高且計算高效的新方法KAML。該方法利用高速可並行的機器學習(xi) 策略解析性狀的複雜程度,機器學習(xi) 過程整合了交叉驗證、多元回歸、網格搜索以及二分求極值等方法,智能化選擇最佳預測模型、最可靠的協變量QTN、最優(you) 的親(qin) 緣關(guan) 係矩陣,多方麵優(you) 化模型以達到最理想的預測準確性。研究結果顯示,KAML具有與(yu) Bayes方法近似的準確性,在部分性狀上甚至表現更好,顯著超過LMM方法,計算效率高於(yu) Bayes方法30-100倍。同時,KAML可與(yu) 動物育種中廣泛應用的一步法(SS,Single Step)策略結合,研究結果顯示SSKAML的預測準確性顯著優(you) 於(yu) SSBLUP方法。另外,對於(yu) 已被KAML分析過的性狀,優(you) 化後的參數可直接用於(yu) 新的群體(ti) 預測,預測準確性幾乎不變,計算效率等同於(yu) LMM方法。KAML和SSKAML可助力動植物基因組育種產(chan) 業(ye) 以及疾病風險預測等人類大健康產(chan) 業(ye) 的發展。
星空体育网站入口官网劉小磊副教授,李新雲(yun) 教授為(wei) 文章共同通訊作者,博士生尹立林為(wei) 論文第一作者,趙書(shu) 紅教授參與(yu) 並指導了該項工作。同時,武漢理工大學袁曉輝教授、博士生張浩浩等共同參與(yu) 了該研究。上述研究工作得到了國家自然科學基金等項目的資助。
KAML軟件:https://github.com/YinLiLin/KAML
全文鏈接:https://genomebiology.biomedcentral.com/articles/10.1186/s13059-020-02052-w



