(通訊員:劉小磊、尹立林、張浩浩)核心提要:2023年2月22日,學院趙書(shu) 紅教授團隊在《Nucleic Acids Research》期刊在線發表了題為(wei) “HIBLUP: An integration of statistical models on the BLUP framework for efficient genetic evaluation using big genomic data”的研究成果文章,被期刊評為(wei) “突破性進展”論文(BreakthroughArticle)。該研究提出了更適合基因組育種大數據計算的“HE+PCG”新策略,開發出高性能計算新工具HIBLUP,為(wei) 開展基因組高效選種及精準選配研究和產(chan) 業(ye) 應用提供了國產(chan) 化利器。
2023年2月22日,國際學術期刊《Nucleic Acids Research》刊登了動物遺傳(chuan) 育種團隊開發的基因組育種大數據計算新工具HIBLUP,中文名為(wei) “天權”。論文題為(wei) “HIBLUP: An integration of statistical models on the BLUP framework for efficient genetic evaluation using big genomic data”,被期刊評為(wei) “突破性進展”論文(BreakthroughArticle)。該研究係統分析了已有遺傳(chuan) 評估算法特點,針對現有算法在處理快速增長的基因組育種大數據時麵臨(lin) 的瓶頸問題,首創基於(yu) V矩陣的“HE+PCG”策略,可完全避免遺傳(chuan) 評估計算過程中的大矩陣求逆,開發出更適合基因組育種大數據時代的高性能計算新工具HIBLUP。與(yu) 現有工具相比,HIBLUP計算速度最快且消耗內(nei) 存最少,而且基因分型個(ge) 體(ti) 在群體(ti) 中占比越大,優(you) 勢愈明顯。此外,HIBLUP軟件功能豐(feng) 富、操作便捷,可運行於(yu) Windows、Linux、macOS等平台,並且全麵適配國產(chan) Kunpeng(鯤鵬)生態。
圖1.HIBLUP論文入選NAR期刊“突破性進展”論文(breakthrough article)
遺傳(chuan) 評估是育種的基礎,隨著基因組育種時代的來臨(lin) ,育種數據規模快速增長,評估算法的計算速度已成為(wei) 育種中的關(guan) 鍵限製因素。遺傳(chuan) 評估主要包括方差組分估計及育種值求解兩(liang) 個(ge) 步驟,其中方差組分估計的計算複雜度高,通常數月或一年更新一次;育種值求解複雜度相對較低,需要日常計算更新。目前,國際現有育種工具(如丹麥的DMU、美國的BLUPF90、英國的ASReml等)采用的評估算法都是以混合模型方程組(Mixedmodelequation, MME)為(wei) 核心,即MME策略,需要求解個(ge) 體(ti) 關(guan) 係矩陣和MME左手項(Lefthandside, LHS)的逆矩陣(如圖2所示)。傳(chuan) 統育種利用係譜構建個(ge) 體(ti) 親(qin) 緣關(guan) 係矩陣,評估過程涉及的矩陣極其稀疏,FSPAK算法(美國專(zhuan) 利)能夠以極快速度求解稀疏矩陣LHS的逆矩陣,是基於(yu) 係譜信息的傳(chuan) 統育種計算必不可少的核心程序。然而,隨著基因組育種時代的來臨(lin) ,個(ge) 體(ti) 親(qin) 緣關(guan) 係矩陣構建逐漸由係譜過渡到基因組信息,關(guan) 係矩陣及LHS矩陣也相應由全稀疏轉變為(wei) 半稠密或全稠密,FSPAK算法並不適用於(yu) 稠密矩陣運算,其劣勢逐漸顯現,雖然FSPAK團隊針對性地做出了優(you) 化,例如,推出了能夠自動鑒別稀疏及稠密塊的FSPAK升級版“YAMS”,以及利用區分核心群和非核心群的方式近似求解基因組個(ge) 體(ti) 關(guan) 係逆矩陣的“APY”策略等,一定程度上提升了數據處理能力,但仍然依賴MME框架,無法避免多次大矩陣的求逆運算,當基因分型個(ge) 體(ti) 規模累計到數十萬(wan) 時,MME策略麵臨(lin) 計算效率低及內(nei) 存需求大的雙重問題,並不能適應基因組大數據時代的育種計算需求。為(wei) 解決(jue) 這一難題,HIBLUP首創基於(yu) 方差協方差V矩陣的“HE+PCG”策略,即利用HE回歸法估計方差組分,采用基於(yu) V矩陣的PCG迭代法估計育種值(如圖2所示),可完全避免遺傳(chuan) 評估計算過程中的大矩陣求逆,並且V矩陣的維度(有表型個(ge) 體(ti) 數)遠低於(yu) MME方程的維度(所有個(ge) 體(ti) 數×遺傳(chuan) 隨機效應個(ge) 數)。因此,無論是計算效率還是內(nei) 存需求上,HIBLUP全麵優(you) 於(yu) 基於(yu) MME策略的現有工具,更適合基因組育種時代的大數據計算。
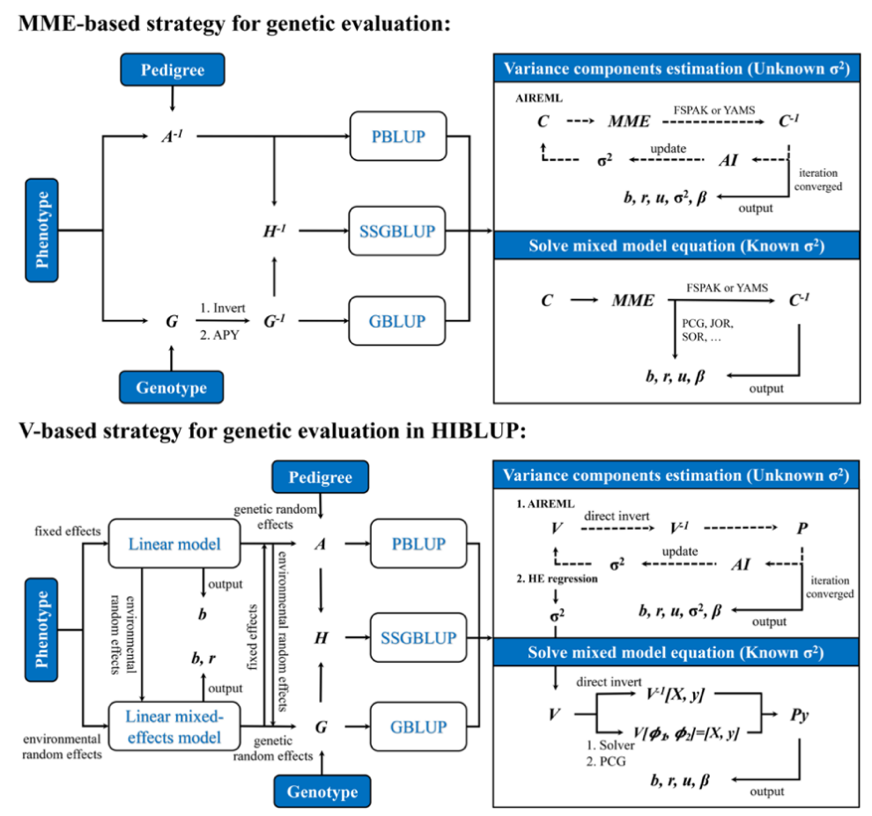
圖2.HIBLUP計算策略與(yu) 國外現有工具MME計算策略的比較。針對基因組大數據的計算特點,HIBLUP首創基於(yu) V矩陣的“HE+PCG”策略,可完全避免遺傳(chuan) 評估計算過程中的大矩陣求逆,且V矩陣的維度相比於(yu) MME方程更小,尤其適用於(yu) 多隨機效應模型,在計算效率和內(nei) 存需求上,HIBLUP全麵優(you) 於(yu) 現有育種計算工具。
HIBLUP針對不同平台鏈接了華為(wei) KML、IntelMKL、OpenBLAS等高性能矩陣數學計算庫,結合OpenMP等多種並行技術提升計算效率,同時運用內(nei) 存映射、單雙精度混合運算等技術,大大降低計算過程中的內(nei) 存消耗。如圖3所示,與(yu) 國際知名育種工具相比,HIBLUP在個(ge) 體(ti) 親(qin) 緣關(guan) 係矩陣構建、單性狀及多性狀模型擬合上,均具有明顯的優(you) 勢,計算速度最快,內(nei) 存消耗最少。通過模擬UKB級別大數據(50萬(wan) 個(ge) 體(ti) 、100萬(wan) 標記)進行測試發現,HIBLUP采用的“HE+PCG”策略能夠在1小時完成方差組分估計及育種值求解,其他軟件需要長達數周甚至數月的時間。此外,通過模擬不同表型個(ge) 體(ti) 數以及不同基因型個(ge) 體(ti) 占比的多種組合方式,對比不同軟件擬合SSGBLUP模型的效率時發現,基因分型個(ge) 體(ti) 在群體(ti) 中占比越大,HIBLUP的計算性能優(you) 勢愈明顯。
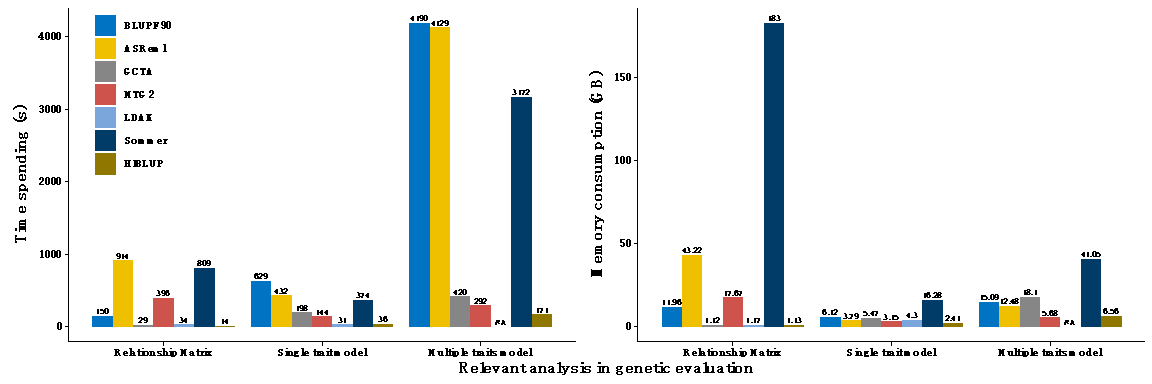
圖3.HIBLUP新工具與(yu) 國外現有工具計算時間及內(nei) 存消耗對比。測試數據集的群體(ti) 大小為(wei) 10000,多性狀模型中性狀個(ge) 數為(wei) 2,均采用32線程並行運算,統一采用GBLUP模型。NA表示對應軟件未實現該功能模塊。
HIBLUP軟件自2018年初全國畜牧總站組織基因組育種算法交流時啟動研發,曆經5年,在功能模塊、計算性能、用戶體(ti) 驗等方麵不斷升級完善,目前已被來自全球50多個(ge) 國家的用戶使用。HIBLUP具備豐(feng) 富的遺傳(chuan) 分析功能,包含常用的單性狀模型、重複記錄模型、多性狀模型等,支持環境互作、遺傳(chuan) 互作、環境與(yu) 遺傳(chuan) 互作等分析,是目前唯一兼具基因組選種及基因組精準選配功能的育種計算工具。HIBLUP不僅(jin) 可運行於(yu) Windows、Linux、MacOS等國外平台,而且全麵適配國產(chan) 華為(wei) Kunpeng(鯤鵬)生態。目前,HIBLUP已在揚翔、中糧、海大、金旭等多個(ge) 大型農(nong) 牧企業(ye) 應用,為(wei) 我國種豬基因組高效選育,以及三元商品豬生產(chan) 精準選配提供了國產(chan) 化新工具。
星空体育网站入口官网博士後尹立林和武漢理工大學博士生張浩浩為(wei) 論文共同第一作者,星空体育网站入口官网趙書(shu) 紅教授、劉小磊教授和李新雲(yun) 教授為(wei) 論文共同通訊作者。該研究受到國家重點研發計劃青年科學家項目、國家自然科學基金、國家生豬體(ti) 係崗位科學家項目的資助。
HIBLUP軟件下載及使用教程網站見:
原文鏈接:



